lucas della torre.
sociología + investigación + datos
análisis + investigación + datos
lucas della torre.
análisis + investigación + datos

¿Amenaza u Oportunidad? Un análisis automatizado de la cobertura mediática sobre el futuro del trabajo y la inteligencia artificial.
¿Amenaza u Oportunidad? Un análisis automatizado de la cobertura mediática sobre el futuro del trabajo y la inteligencia artificial.
Este proyecto responde a la pregunta de cómo se debate sobre la Inteligencia Artificial en medios digitales mediante la construcción de una herramienta de análisis de opinión pública. Se desarrolló un flujo automatizado en n8n que utiliza IA (Gemini) para aplicar un marco de análisis sociológico a la cobertura mediática, yendo más allá del simple sentimiento para identificar los "marcos discursivos" dominantes. El análisis de más de 60 noticias revela una fuerte inclinación hacia la cautela y el riesgo, ofreciendo una visión cuantitativa y cualitativa de las narrativas que moldean la percepción pública sobre esta tecnología.

💼 Rol: Analista de datos de opinión pública.
🗄️ Fuente de datos: Google News (vía RSS Feeds).
⚙️ Procesamiento IA: Google Gemini 2.5 Pro.
🛠️ Automatización: N8N Self-hosted.
📅 Fecha de Realización: Agosto 2025.
💼 Rol: Analista de datos de opinión pública.
🗄️ Fuente de datos: Google News (vía RSS Feeds).
⚙️ Procesamiento IA: Google Gemini 2.5 Pro.
🛠️ Automatización: N8N Self-hosted.
📅 Fecha de Realización: Agosto 2025.
1. Un discurso dominado por la cautela
Análisis del discurso en medios sobre IA
El análisis de 62 noticias relevantes sobre 'IA y trabajo' revela que la conversación mediática en Argentina es abrumadoramente cautelosa. El 82% de la cobertura se concentra en los marcos discursivos de 'Amenaza / Riesgo Laboral' y 'Debate Ético / Social', mientras que la narrativa 'Tecno-optimista' representa apenas un 14% del total.
2. Definiendo el debate: Las 4 categorías de análisis
Para ir más allá de un simple análisis de sentimiento (positivo/negativo), este proyecto utilizó un marco de análisis sociológico para clasificar cada noticia. Tras una revisión preliminar del discurso y basándose en los debates actuales sobre tecnología y trabajo, se desarrollaron 4 marcos discursivos principales. Estos permiten capturar los diferentes ángulos y enfoques desde los cuales los medios de comunicación están presentando el impacto de la inteligencia artificial. Estas fueron las categorías utilizadas para entrenar al agente de IA:
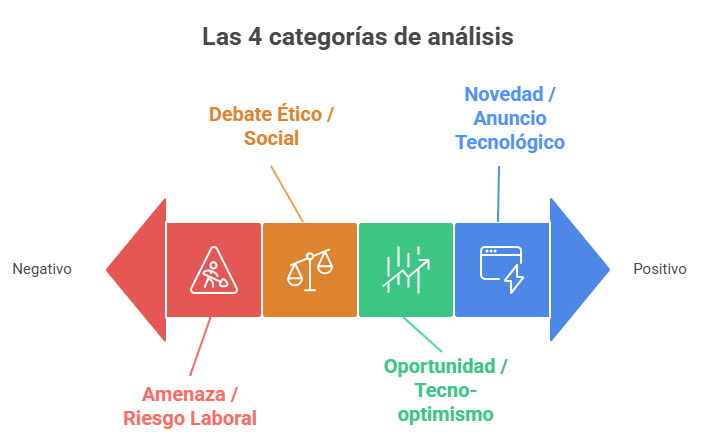
Amenaza / Riesgo Laboral: En esta categoría se agruparon aquellos artículos enfocados en la sustitución de empleos, la automatización de tareas que antes eran humanas, la precarización, devaluación de habilidades existentes y los desafíos económicos directos para los trabajadores y el mercado laboral.
Debate Ético / Social: Este marco incluye las conversaciones sobre las consecuencias sociales más amplias de la IA. Abarca temas como los sesgos algorítmicos, la privacidad de los datos, la necesidad de regulación, la desigualdad social que puede generar y el impacto general en la estructura de la sociedad.
Oportunidad / Tecno-optimismo: Aquí se clasifican las noticias que presentan a la IA como una herramienta de progreso y crecimiento. Se centra en el aumento de la productividad, la creación de nuevos roles y empleos, la resolución de problemas complejos, la innovación y las oportunidades de inversión y desarrollo económico.
Novedad / Anuncio Tecnológico: Esta categoría agrupa los textos de carácter principalmente informativo y neutral. Suelen ser noticias sobre el lanzamiento de un nuevo modelo de IA, una nueva funcionalidad de una empresa tecnológica o reportes de eventos, pero sin un enfoque analítico profundo o juicio de valor sobre sus implicaciones laborales o sociales.
3. Análisis Cualitativo: ¿Qué se esconde detrás de los números?
El análisis revela que la conversación mediática no es monolítica. Se estructura en cuatro narrativas principales, cada una con un ángulo y una perspectiva diferente sobre el impacto de la IA en el trabajo.
La Narrativa de la Amenaza: El Discurso de la Sustitución
El discurso dominante se enfoca en la sustitución del trabajo humano. Los titulares utilizan un lenguaje directo que cuantifica el riesgo, nombra profesiones específicas y enmarca a la IA como un actor económico que compite y desplaza empleos.
"Estos son los empleos que más rápido desaparecerán en 2030 con el auge de la inteligencia artificial" - Infobae 10/01/2025
El Debate Cauteloso: El Discurso en Modo Interrogativo
Una parte significativa del debate se presenta con cautela periodística. En lugar de hacer afirmaciones, los medios utilizan el "modo interrogativo" para explorar las consecuencias sociales y éticas, reflejando la incertidumbre sobre el tema.
"Inteligencia Artificial: ¿y si su uso nos está haciendo más tontos?" - Diario Clarín 21/02/2025
El Optimismo de Nicho: Una Oportunidad para Pocos
La narrativa tecno-optimista es minoritaria y no se enfoca en un beneficio general, sino en una oportunidad económica concentrada en un nicho de especialistas, como los altos salarios para nuevos roles vinculados a la IA.
"Cómo usar la IA para encontrar tu próximo trabajo" La Nación 05/06/2025
La Narrativa de la Adaptación: Educación y Nuevas Habilidades
Como respuesta directa a la amenaza, emerge un discurso enfocado en la solución: la capacitación y el desarrollo de nuevas habilidades ("reskilling"). Esta narrativa se centra en las "carreras del futuro" y la necesidad de adaptarse al nuevo paradigma.
"Cómo la IA está transformando la carrera profesional y otras tendencias laborales" - The World Economic Forum 06/05/2025
4. La arquitectura de la información: Un pipeline de datos
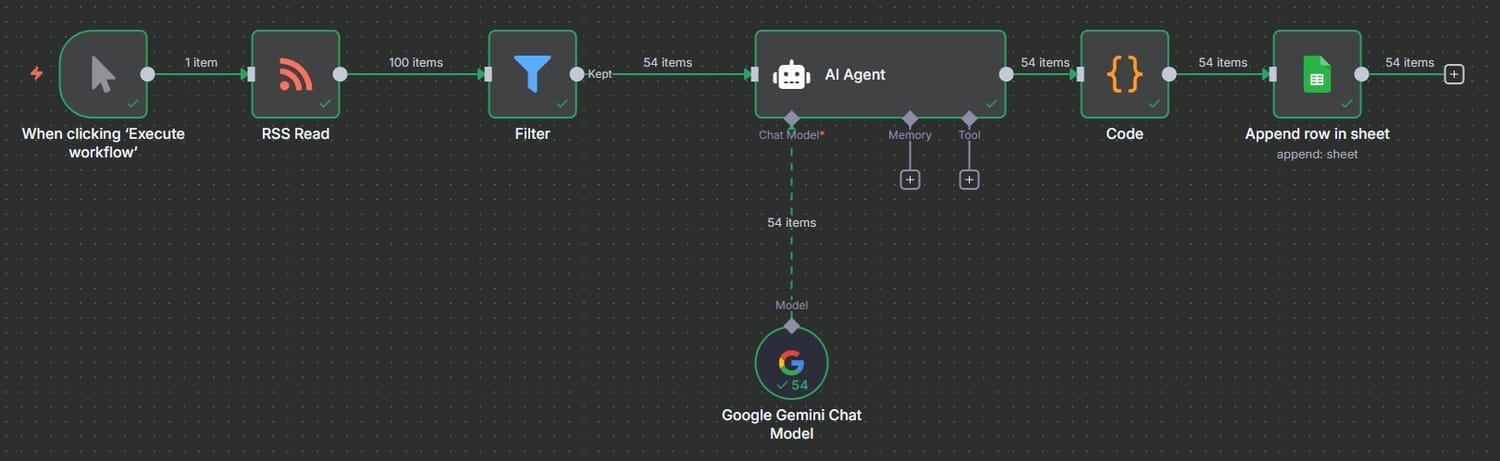
Esta imagen muestra el mapa completo del pipeline de datos automatizado que construí en n8n para potenciar este análisis. El proceso funciona como una línea de ensamblaje inteligente:
Recolección: El flujo comienza leyendo las noticias más recientes sobre "IA y trabajo" directamente desde un feed personalizado de Google Noticias.
Filtrado: Un primer filtro inteligente descarta automáticamente el "ruido", dejando pasar únicamente los artículos que contienen palabras clave relevantes.
Análisis IA: Cada noticia filtrada es enviada a un Agente de IA (potenciado por Gemini), que la lee, la interpreta y la clasifica en uno de los cuatro marcos discursivos siguiendo las reglas de un prompt diseñado a medida.
Limpieza y estructuración: Un nodo de código se encarga de limpiar y estandarizar la respuesta de la IA, dejándola en un formato JSON perfecto.
Almacenamiento: Finalmente, el resultado completo del análisis se guarda automáticamente como una nueva fila en la hoja de Google Sheets que sirve como base de datos para este estudio.
Todo este proceso transforma información no estructurada de internet en una base de datos analítica, limpia y ordenada, de forma completamente autónoma.
5. Conclusiones, preguntas y escalabilidad
Conclusiones
Este proyecto demostró con éxito la viabilidad de construir un pipeline de datos automatizado para realizar un análisis de discurso sociológico a gran escala.
El análisis cuantitativo reveló una clara hegemonía del discurso de riesgo y debate (más del 80%) en la cobertura mediática sobre la IA y el trabajo, mientras que el análisis cualitativo permitió identificar los patrones narrativos específicos detrás de estos números: la "sustitución" como amenaza principal, la "cautela" como postura periodística y la "oportunidad" como un beneficio de nicho.
La herramienta construida en n8n probó ser un método eficaz y escalable para acelerar drásticamente los procesos de investigación, transformando información no estructurada de internet en una base de datos analítica y accionable.
Preguntas:
El flujo construido en n8n es modular y altamente adaptable. Así como se utilizó un feed general de Google Noticias, la herramienta podría configurarse para "escuchar" fuentes de nicho (papers académicos para un grupo de investigación, por ejemplo) para realizar análisis de un sector en particular.
Del mismo modo, el agente de IA podría ser re-entrenado con un nuevo set de marcos discursivos para analizar otros temas, como la percepción sobre el cambio climático, una nueva política económica o la reputación de una marca.
Aquí otros ejemplos a los cuales el pipeline de análisis discursivo puede adaptarse:
Consultoras de opinión pública:
Encuestas
Entrevistas en profundidad (transcripciones).
Grupos focales (grabaciones pasadas a texto).
Redes sociales (tweets, comentarios de notas periodísticas).
Empresas:
Reseñas de apps (Play Store, App Store).
Encuestas de satisfacción (NPS, CSAT).
Comentarios en redes sociales (Instagram, Facebook).
Focus groups o entrevistas con clientes.
Tickets de soporte (lo que los clientes escriben cuando realizan quejas o solicitan ayuda).
Este análisis se centró en el "discurso mediático". El siguiente paso natural y más potente de esta investigación sería contrastar estos hallazgos con la "opinión pública" orgánica.
Para ello, el pipeline podría expandirse para conectarse a la API de Twitter/X u otras redes sociales, recolectando y analizando los comentarios y posts de los usuarios sobre el mismo tema.
Esto permitiría medir la brecha o la consonancia entre lo que los medios publican y lo que la gente realmente opina, ofreciendo un mapa del debate público mucho más completo.
Para medir y mejorar la precisión del modelo de IA en esta tarea, el proceso comenzaría creando un "set de validación", es decir, una muestra de noticias clasificadas manualmente que sirva como nuestra "fuente de la verdad".
Con esta base, se podrían comparar las clasificaciones de la IA con las manuales para calcular métricas de rendimiento estándar en Machine Learning, como la Precisión (Accuracy) y la Puntuación F1 (F1-Score).
Sin embargo, el paso más importante sería el análisis de los errores para entender en qué categorías se equivoca más el modelo, lo que nos permitiría iterar y refinar el prompt del agente, añadiendo ejemplos o clarificando las definiciones para robustecer su capacidad de clasificación de forma continua.
Escalabilidad y Pasos Futuros
El pipeline desarrollado en n8n fue diseñado con la escalabilidad en mente. Aunque este análisis representa una "fotografía" de un momento específico, su arquitectura permite transformarlo fácilmente en un producto de datos continuo.
El siguiente paso natural sería reemplazar el trigger manual por un Schedule Trigger para una ejecución autónoma y migrar el almacenamiento de Google Sheets a una base de datos más robusta como PostgreSQL, lo que permitiría manejar un gran volumen de datos históricos.
Una vez establecido este observatorio, se podrían expandir las fuentes de datos para incluir la "opinión pública" real, integrando la API de Twitter/X, y finalmente conectar la base de datos a una herramienta de BI como Looker Studio para crear un dashboard interactivo en tiempo real capaz de monitorear tendencias y medir el impacto de eventos de forma continua.
lucas della torre.

2025 © Todos los derechos reservados.